Pairwise Document Similarity in Large Collections with MapReduce.這是一篇由UMD的一位博士生Tamer M. Elsayed和他的指導教授所共同發表在「ACL-08: HLT」的短篇論文,主要用「MapReduce」來處理大量文件相似度的計算,如果您對這篇論文有興趣的話,請參考上述論文連結,筆者不再詳述。
下述筆者撰寫的驗證程式需要用到「Cloud9 - A MapReduce Library for Hadoop」,「Cloud9」是由UMD所開發的,主要用來作為課程的教學工具和一些文字處理方面的研究,它採用Apache License,所以您可以直接用Subversion checkout下來使用,而下述範例主要用到「PairOfIntString」和「ArrayListWritable」。
Pairwise Document Similarity
在進行「Pairwise Similarity」的「Map」階段時,筆者純粹利用Regular Expression來處理~ 這並不是最佳的處理方式(我承認偷懶~),最佳的方式應該撰寫一些特定的「OutputFormat」和「Writable」來加以處理,整個效率才會大大的提高!(如:Cloud9所提供的Tuple)
由於此範例需要處理二次的MapReduce,所以筆者直接利用「job2.addDependingJob(job1);」將兩個Job產生相依性,也就是先執行job1完成之後JobControl才會去呼叫job2開始執行。
import java.io.IOException;
import java.util.*;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.mapred.jobcontrol.Job;
import org.apache.hadoop.mapred.jobcontrol.JobControl;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import edu.umd.cloud9.io.ArrayListWritable;
import edu.umd.cloud9.io.PairOfIntString;
public class PairwiseDS extends Configured implements Tool
{
public static class Map extends MapReduceBase implements
Mapper<LongWritable, Text, Text, PairOfIntString>
{
private Text word = new Text();
public void map(LongWritable key, Text value,
OutputCollector<Text, PairOfIntString> output, Reporter reporter)
throws IOException
{
FileSplit fileSplit = (FileSplit) reporter.getInputSplit();
String fileName = fileSplit.getPath().getName();
fileName = fileName.substring(0, fileName.length() - 4);
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens())
{
word.set(tokenizer.nextToken());
output.collect(word, new PairOfIntString(1, fileName));
}
}
}
public static class Reduce extends MapReduceBase implements
Reducer<Text, PairOfIntString, Text, ArrayListWritable>
{
public void reduce(Text key, Iterator<PairOfIntString> values,
OutputCollector<Text, ArrayListWritable> output,
Reporter reporter) throws IOException
{
ArrayList<PairOfIntString> al = new ArrayList<PairOfIntString>();
HashMap<String, Integer> map = new HashMap<String, Integer>();
while (values.hasNext())
{
PairOfIntString psi = values.next();
if (map.containsKey(psi.getRightElement()))
{
Integer i = (Integer) map.get(psi.getRightElement());
map.put(psi.getRightElement(), i.intValue() + 1);
} else
{
map.put(psi.getRightElement(), psi.getLeftElement());
}
}
Iterator i = map.entrySet().iterator();
while (i.hasNext())
{
java.util.Map.Entry m = (java.util.Map.Entry) i.next();
al.add(new PairOfIntString((Integer) m.getValue(), (String) m
.getKey()));
}
output.collect(key, new ArrayListWritable<PairOfIntString>(al));
}
}
public static class Map2 extends MapReduceBase implements
Mapper<LongWritable, Text, Text, IntWritable>
{
private Text word = new Text();
public void map(LongWritable key, Text value,
OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException
{
String line = value.toString().trim();
ArrayList<String> keyList = new ArrayList<String>();
ArrayList<Integer> valList = new ArrayList<Integer>();
String p = "\\(([0-9]+), ([a-z0-9.]+)\\)";
Pattern r = Pattern.compile(p);
Matcher m = r.matcher(line);
while (m.find())
{
String k = m.group(2);
String v = m.group(1);
keyList.add(k);
valList.add(new Integer(v));
}
if (keyList.size() > 1)
{
String[] key_arr = keyList.toArray(new String[0]);
Integer[] val_arr = valList.toArray(new Integer[0]);
int klen = key_arr.length;
for (int i = 0; i < klen; i++)
{
for (int j = i + 1; j < klen; j++)
{
word.set(key_arr[i] + "," + key_arr[j]);
output.collect(word, new IntWritable(val_arr[i]
* val_arr[j]));
}
}
}
}
}
public static class Reduce2 extends MapReduceBase implements
Reducer<Text, IntWritable, Text, IntWritable>
{
public void reduce(Text key, Iterator<IntWritable> values,
OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException
{
int sum = 0;
while (values.hasNext())
{
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}
public int run(String[] args) throws Exception
{
// ===================== Indexing =====================
JobConf conf = new JobConf(getConf(), PairwiseDS.class);
conf.setJobName("Indexing");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(PairOfIntString.class);
conf.setMapperClass(Map.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
conf.setNumReduceTasks(1);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
TextOutputFormat.setOutputPath(conf, new Path(args[1]));
Job job1 = new Job(conf);
// ===================== Pairwise Similarity =====================
JobConf conf2 = new JobConf(getConf(), PairwiseDS.class);
conf2.setJobName("Pairwise Similarity");
conf2.setOutputKeyClass(Text.class);
conf2.setOutputValueClass(IntWritable.class);
conf2.setMapperClass(Map2.class);
conf2.setReducerClass(Reduce2.class);
conf2.setInputFormat(TextInputFormat.class);
conf2.setOutputFormat(TextOutputFormat.class);
conf2.setNumReduceTasks(1);
FileInputFormat.setInputPaths(conf2, new Path(args[1] + "/p*"));
TextOutputFormat.setOutputPath(conf2, new Path(args[2]));
Job job2 = new Job(conf2);
job2.addDependingJob(job1);
JobControl controller = new JobControl("Pairwise Document Similarity");
controller.addJob(job1);
controller.addJob(job2);
new Thread(controller).start();
while (!controller.allFinished())
{
System.out.println("Jobs in waiting state: "+ controller.getWaitingJobs().size());
System.out.println("Jobs in ready state: "+ controller.getReadyJobs().size());
System.out.println("Jobs in running state: "+ controller.getRunningJobs().size());
System.out.println("Jobs in success state: "+ controller.getSuccessfulJobs().size());
System.out.println("Jobs in failed state: "+ controller.getFailedJobs().size());
System.out.println();
try
{
Thread.sleep(20000);
} catch (Exception e)
{
e.printStackTrace();
}
}
return 0;
}
public static void main(String[] args) throws Exception
{
int res = ToolRunner.run(new Configuration(), new PairwiseDS(), args);
System.exit(res);
}
}
after Indexing:
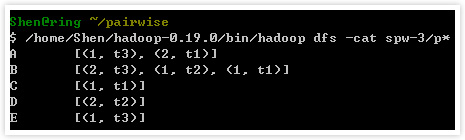
after Pairwise Similarity:

相關資源